[PL] HEVD Stack Buffer Overflow #1 - Wprowadzenie
Wprowadzenie
Ten post rozpoczyna serię w której eksplorować będę podatność przepełnienia stosu w sterowniku HEVD (HackSys Extreme Vulnerable Driver). Jest to sterownik ze znanymi podatnościami stworzony m.in. do nauki eksploatacji. Moim celem jest uzyskanie LPE z poziomu zwykłego użytkownika do poziomu SYSTEM (nt authority\system).
Środowisko
Guest
- VMWare Workstation Pro 25H2 (25.0.0…)
- Windows 10 Pro 22H2 (Guest, AMD-V, Build 19045.3803)
- Memory Integrity / Core Isolation: Off
- HEVD v3.00
Host
- Windows 11 Home (Host, Bare-metal)
- WinDbg 1.2511.21001.0
- Microsoft (R) C/C++ Optimizing Compiler Version 19.44.35219 for x64
- Microsoft (R) Macro Assembler (x64) Version 14.44.35219.0
- ropper
- masm2c
- ghidra
Moim zdaniem najlepszym tutorialem do setupu środowiska z użyciem WinDbg jest ten Post / Video
Początkowo podjąłem próby ustawienia środowiska na platformie VirtualBox. Niestety pomimo moich wszelkich starań, nie udało mi się przenieść zawartości rejestru procesora CR4 na maszynę wirtualną. Jeżeli komuś z was uda się ten wyczyn, proszę o kontakt ;)
Ocena podatności
Podatność stack buffer overflow znajduje się w funkcji TriggerBufferOverflowStack.
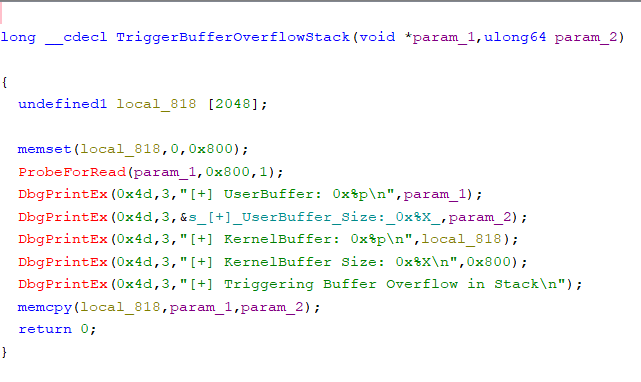
Powyższy screenshot pochodzi z narzędzia do inżynierii wstecznej Ghidra.
Funkcja TriggerBufferOverflowStack bierze dwa argumenty:
void *param1to wskaźnik na miejsce w pamięciulong64 param2to rozmiar danych w pamięci
Zdefiniowana jest zmienna lokalna przechowywana na stosie
undefined1 local_818[2048].
Podatność znajduje się w funkcji memcpy: memcpy(local_818,param_1,param_2);
Funkcja ta kopiuje param_2 bajtów z miejsca w pamięci zdefiniowanego przez param_1 do zmiennej na stosie local_818. Jako że kontrolujemy zarówno zawartością param_1 jak i wartością param_2, możemy nadpisać stos dowolnym ciągiem bajtów o dowolnej wyznaczonej długości.
Powoduje to przepełnienie stosu, stąd wysoce prawdopodobna jest możliwość nadpisania adresu powrotu funkcji.
Analiza z poziomu assemblera
Ze względu na czytelność oraz informacje dla nas potrzebne, pominę instrukcje związane z debuggowaniem. Skupię się na tym co istotne.
Pierwsze instrukcje zapisują stan rejestrów RBX, RSI, RDI w tzw. Shadow Space.
1
2
3
MOV qword ptr [RSP + 8h], RBX
MOV qword ptr [RSP + 10h], RSI
MOV qword ptr [RSP + 18h], RDI
W samym RSP w tym momencie znajduje się adres powrotu funkcji.
Na stos zapisujemy stan rejestrów R12, R14, R15.
1
2
3
PUSH R12
PUSH R14
PUSH R15
Wartości param_1 oraz param_2 przekazane zostały do funkcji w rejestrach odpowiednio RCX i RDX zgodnie ze standardową konwencją wywoływania w x64. Tworzone są kopie wartości w rejestrach RDI oraz RSI.
1
2
MOV RSI, RDX; (param_2)
MOV RDI, RCX; (param_1)
Rezerwujemy 2080 bajtów. 2048 na naszą zmienną, oraz 32 na Shadow Space dla wywoływanych funkcji.
1
SUB RSP, 820h
Poniższa funkcja ustawia zawartość bajtów w zmiennej lokalnej na zera.
1
2
3
4
5
MOV R12D, 800h
MOV R8D, R12D; (_Size)
XOR RDX, RDX; (_Val)
LEA RCX, [RSP + 20h ]; (_Dst)
CALL memset
Doszliśmy do rozkazu memcpy.
1
2
3
4
MOV R8, RSI; (_Size)
MOV RDX, RDI; (_Src)
LEA RCX, [RSP + 20h ]; (_Dst)
CALL memcpy
Uwzględniając wszystkie podane wcześniej rozkazy, stos przed wykonaniem memcpy wygląda następująco:
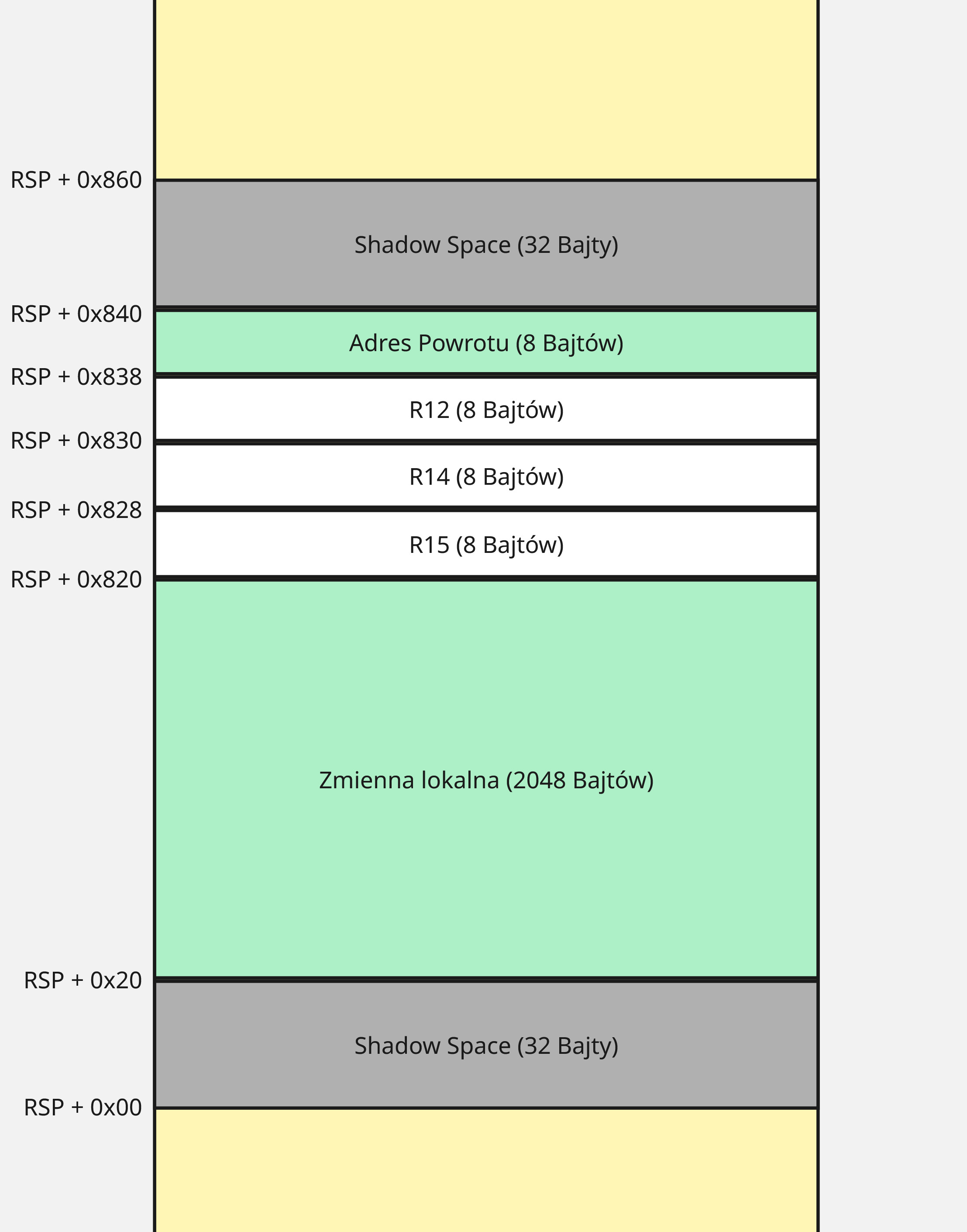
Z tego miejsca jesteśmy w stanie określić potrzebny rozmiar przepełnienia zmiennej lokalnej by nadpisać adres powrotu. Wartość ta to 2080 bajtów (2048 + 4 * 8).
Ostatnim fragmentem kodu jest powrót. Jeżeli wywołanie memcpy zakończy się powodzeniem, wykonywane są poniższe rozkazy:
1
2
3
4
5
6
7
8
9
10
MOV EAX, EBX
LEA R11, [RSP + 820h ]
MOV RBX, qword ptr [R11 + 20h ]
MOV RSI, qword ptr [R11 + 28h ]
MOV RDI, qword ptr [R11 + 30h ]
MOV RSP, R11
POP R15
POP R14
POP R12
RET
Krótko mówiąc odzyskiwane są wartości rejestrów ze stosu oraz shadow space, następnie wykonywany jest powrót.
Tu rodzi się problem. Rejestry R12-R15 są uznawane za non-volatile, co oznacza że jeżeli wrócimy do funkcji wywołującej (caller) ze zmienioną zawartością tych rejestrów, możemy napotkać nieoczekiwane zachowania.
Dodatkowo, jako że jesteśmy na Windowsie 10 (z domyślnie włączonym mechanizmem SMEP), będziemy prawdopodobnie potrzebować więcej niż jeden adresu powrotu (mały foreshadowing), tym samym nadpiszemy kolejne potrzebne do poprawnego powrotu rejestry znajdujące się tuż nad adresem powrotu.
Informacje te trzeba wziąć pod uwagę w momencie chęci powrotu do programu wywołującego przerwanie systemowe.
Analiza kodu w assemblerze dała nam zdecydowanie większy ogląd na działanie funkcji w sterowniku, oraz ujawniła potencjalne problemy, które rozwiązać będziemy próbować w następnych postach :).